Объект тип (Type Object)
Задача
Сделать более гибким создание новых "классов" с помощью создания класса, каждый экземпляр которого может представлять собой другой тип объекта.
Мотивация
Давайте представим себе, что мы работаем над фентезийной ролевой игрой. Нам нужно написать код для орд разнообразных монстров, которые рыщут вокруг и желают растерзать нашего героя. У монстров есть несколько разных атрибутов: здоровье, атака, графика, звуки и т.д., но в качестве примера мы будем беспокоиться только о первых двух.
У каждого монстра в игре есть значение текущего здоровья. Начинает он с полным и каждый раз, когда монстр получает ранение, оно уменьшается. Еще у монстра есть строка атаки. Когда он будет атаковать нашего героя, этот текст будет демонстрироваться пользователю. (Сейчас для нас это не важно.)
Дизайнеры сказали нам что монстры бывают разных родов. Например "драконы" или "тролли". Каждый род описывает тип монстра, существующего в игре и у нас в подземелье одновременно может быть множество монстров одного рода.
Род определяет начальное здоровье монстра: дракон начинает с большим значением, чем тролль и соответственно убить его сложнее. Также он определяет строку атаки: все монстры одного рода атакуют одинаково.
Типичное ООП решение
Получив такой игровой дизайн, мы запускаем текстовый редактор и начинаем кодить. В соответствии с дизайном, дракон — это тип монстра, а тролль — еще один тип и т.д для всех родов. Думая в объектно-ориентированном стиле мы придем к базовому классу Monster.
Это так называемое публичное наследование или "is-a" отношение (один класс является подклассом другого). В рамках традиционного
ООПмышления, так как дракон "is-a" (является) монстром, мы моделируем это отношение делаяDragonподклассомMonster. Как мы увидим позже создание подкласса — это единственный способ организации такого отношения в коде.
class Monster
{
public:
virtual ~Monster() {}
virtual const char* getAttack() = 0;
protected:
Monster(int startingHealth)
: health_(startingHealth)
{}
private:
int health_; // Текущее значение здоровья
};
Публичная функция getAttack() позволяет боевому коду получать строку, которую нужно показывать когда монстр атакует героя. Каждый класс рода будет классом наследником, переопределяющим этот класс и предоставляющим свое сообщение.
Конструктор является защищенным и устанавливает начальное значение для здоровья монстра. Для каждого рода у нас есть свой унаследованный класс, предоставляющий свой публичный конструктор, вызывающий базовый и устанавливающий соответствующее роду начальное значение здоровья.
А теперь рассмотрим несколько подклассов родов:
class Dragon : public Monster
{
public:
Dragon() : Monster(230) {}
virtual const char* getAttack() {
return "Дракон выдыхает огонь!";
}
};
class Troll : public Monster
{
public:
Troll() : Monster(48) {}
virtual const char* getAttack() {
return "Троль ударяет дубиной!";
}
};
Восклицательный знак делает все еще более захватывающим!
Каждый унаследованный от класса Monster передает в базовый класс стартовое здоровье и переопределяет getAttack(), чтобы возвращать правильную для рода строку. Все работает как надо и довольно скоро мы сможем увидеть нашего героя убивающим всех этих монстров. Мы продолжаем писать код и прежде чем опомниться, у нас будут дюжины подклассов монстров, начиная с кислотных слизней и заканчивая зомби-козлами.
А затем мы начнем вязнуть. Нашим дизайнерам хочется иметь сотни родов и если продолжать в том же духе, нам придется всю жизнь прописывать эти семь строчек для нового подкласса и перекомпилировать игру. Или что еще хуже, дизайнерам захочется слегка подкорректировать уже существующие рода монстров. И теперь вся наша продуктивная работа свелась к тому что мы:
Получаем письмо от дизайнера, который просит изменить здоровье с
48на52.Ищем и изменяем
Troll.h.Перекомпилируем игру.
Проверяем изменение.
Отвечаем на письмо.
Повторяем.
В результате день испорчен. Мы превратились в обезьянку с данными. Наши дизайнеры расстроены тем, что для простого изменения числового значения им приходится ожидать целую вечность. Что нам нужно, так это возможность изменять характеристики рода без перекомпиляции игры каждый раз. Более того, нам бы хотелось, чтобы дизайнеры могли изменять настройки самостоятельно, вообще без помощи программиста.
Класс для класса
На самом высшем уровне проблема, которую мы хотим решить, чрезвычайно проста. У нас в игре есть куча монстров и мы хотим сделать часть данных общей среди них. Нашего героя атакует орда монстров и мы хотим, чтобы некоторые из них имели одинаковую строку атаки. Мы будем считать, что все эти монстры относятся к одному "роду", и этот род определяет строку атаки.
Мы решили реализовать эту концепцию с помощью наследования, так как это хорошо согласуется с нашим интуитивным пониманием ситуации: если дракон — это монстр, значит каждый дракон в игре будет экземпляром "класса" дракон. Объявим каждый род в виде подкласса абстрактного базового класса Monster и, как следствие, каждый монстр в игре будет экземпляром этого унаследованного класса. В результате у нас получится примерно такая иерархия:
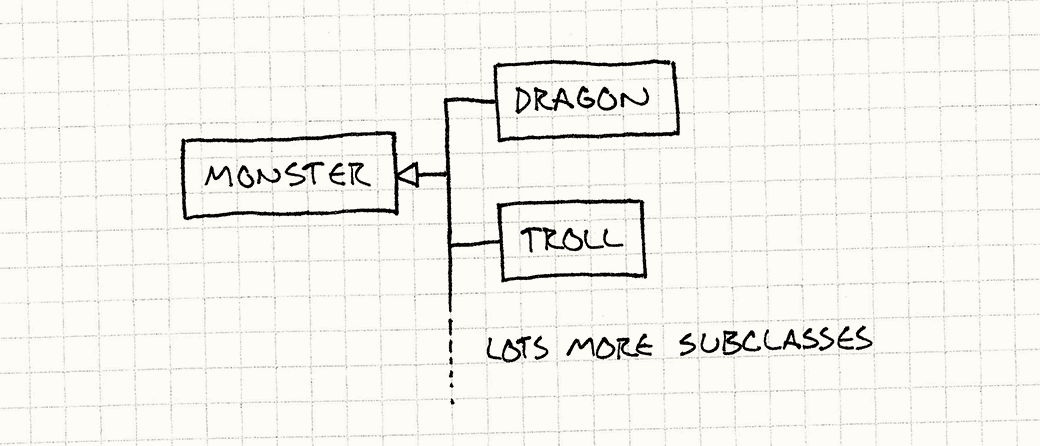
здесь ![]() означает "наследуется от".
означает "наследуется от".
Каждый экземпляр монстра в игре будет представлять собой один из унаследованных типов монстров. Чем больше у вас родов, тем больше иерархия классов. Конечно это проблема: добавление новых родов означает добавление нового кода и каждый род должен компилироваться как отдельный тип.
Этот подход работает, но это только один из вариантов. Мы можем спроектировать наш код и таким образом, что каждый монстр будет содержать (has-a) род. Вместо того, чтобы создавать подкласс Monster для каждого рода, у нас будет простой класс Monster и единственный класс Breed.
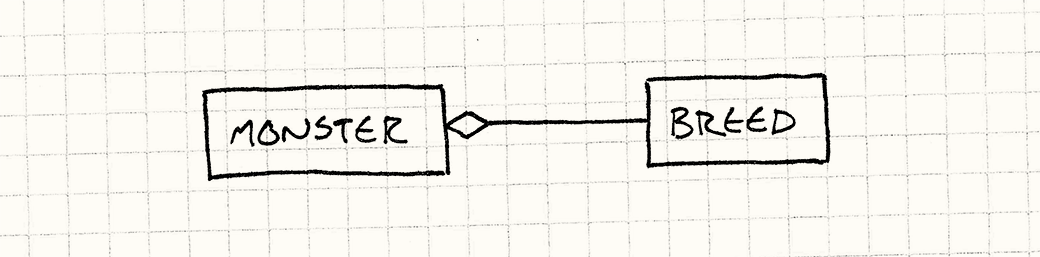
Здесь ![]() означает "имеется ссылка от"
означает "имеется ссылка от"
Вот и все. Два класса. Обратите внимание, что здесь нет вообще никакого наследования. В такой системе каждый монстр в игре просто будет экземпляром класса Monster. Класс Breed содержит информацию, общую для всех монстров одного рода: начальное здоровье и строка атаки.
Чтобы ассоциировать монстра с родом, мы дадим каждому экземпляру Monster ссылку на объект Breed с информацией об этом роде. Чтобы получить строку атаки, монстр просто вызывает метод своего рода. Класс Breed по сути определяет "тип" монстра. Каждый экземпляр рода является объектом, представляющим отдельный концептуальный тип, как следует из имени шаблона: Объект тип.
Что в этом шаблоне самое замечательное, так это то, что теперь мы можем определять новые типы без усложнения кодовой базы: мы просто перенесли часть информации о типе из жестко закодированной иерархии классов в данные, которые можно определить во время работы программы.
Мы можем создать сотни разных видов просто создав больше экземпляров Breed с разными значениями. Если мы создаем экземпляр рода на основе данных, прочитанных из файла конфигурации, у нас появится возможность определять новый тип монстра полностью в данных. Это так просто, что дизайнерам точно понравится!
Шаблон
Определим класс объект тип и класс типизированного объекта. Каждый экземпляр объекта типа представляет отдельный логический тип. Каждый типизированный объект хранит ссылку на объект тип, описывающий его тип.
Специфичные для экземпляра данные хранятся в экземпляре типизированного объекта, а общие для всех экземпляров этого концептуального типа данные хранятся в объекте типе. Объекты, ссылающиеся на один и тот же объект тип, будут себя вести как если бы они были одного типа. Это позволит нам разделять данные и поведение между набором схожих объектов, примерно в том же духе как это делают подклассы, но без жестко закодированной структуры наследования.
Когда использовать
Этот шаблон полезен везде, где необходимо определять множество различных "видов" вещей, но жесткое их определение с помощью средств типизации вашего языка будет слишком строгим. В частности это полезно в следующих случаях:
Вы не знаете какие типы вам понадобятся. (Что например, если нашей игре понадобится поддерживать загружаемый контент, содержащий новые рода или монстров?)
Вы хотите иметь возможность изменять или добавлять новые типы без перекомпиляции или изменения кода.
Имейте в виду
Этот шаблон посвящен замене определения "типа" с императивного, но жесткого способа с помощью самого языка на более гибкий, но менее поведенческий мир объектов в памяти. Гибкость — это хорошо, но перемещая определение типа в данные, вы кое-что теряете.
За типом объекта придется следить вручную
Одно из преимуществ использования C++ подобной системы типов в том, что компилятор занимается всей бухгалтерией классов автоматически. Данные, определяющий каждый класс, автоматически компилируются в статические сегменты памяти внутри исполнимого файла и просто работают.
Применяя шаблон Объект тип, мы теперь сами отвечаем не только за управление нашими монстрами в памяти, но и за их типы: нам нужно следить за тем, чтобы объекты рода были инициализированы и находились в памяти все время, пока они будут нужны монстрам. Когда мы создаем нового монстра, мы должны быть уверены что правильно его инициализировали и указали для него правильный род.
Мы избавились от некоторых ограничений компилятора, но взамен нам придется делать кое-что из того, что он раньше делал за нас.
Если заглянуть под капот
C++, виртуальные классы там реализуются с помощью структуры, называемой "таблица виртуальных функций" (virtual function table) или просто "vtable". vtable — это простая структура, содержащая набор указателей на функции, по одному на каждый виртуальный метод в классе. Для каждого класса в памяти хранится отдельная таблица. Каждый экземпляр класса обладает указателем на виртуальную таблицу своего класса.Когда вы вызываете виртуальную функцию, код сначала выполняет поиск в виртуальной таблице объекта, а потом вызывает функцию, хранящуюся в соответствующем указателе на функцию в таблице.
Знакомо звучит? Виртуальная таблица — это наш объект рода, а наш указатель в виртуальной таблице — это ссылка, с помощью которой монстр ссылается на свой род. Классы
C++— это шаблон Объект Тип, реализованный наСи автоматически обрабатываемый компилятором.
Нам будет сложнее определить поведение каждого типа
Используя подклассы, вы можете переопределить метод и вообще сделать все что угодно: вычислить значение процедурно, вызвать другой код и т.д. Никаких ограничений. Если у нас возникнет такое желание, мы даже можем определить подкласс монстра, строка атаки которого изменяется на основе фазы луны. (Я думаю для оборотней — это то, что нужно).
Однако когда мы используем шаблон Объект тип, мы заменяем переопределенный метод переменной членом. Вместо того, чтобы наш монстр был подклассом, переопределяющим метод для вычисления строки атаки с использованием другого кода, у нас будет объект рода, который хранит строку атаки в другой переменной.
Это значительно упрощает использование объекта типа для определения типо-специфичных данных, но усложняет определение типо-специфичного поведения. Если, например, различные рода монстров нуждаются в разных алгоритмах ИИ, использование этого шаблона усложняется.
Есть несколько способов избежать эти ограничения. Проще всего иметь фиксированный набор предопределенных вариантов поведения и дальше использовать данные в объекте типа для выбора одного из них. Пускай, например, ИИ монстров может быть в состояниях "стоять на месте","преследовать героя", "скулить и прятаться в страхе" (не все же они могучие драконы). Мы можем определить функции для реализации каждой из этих линий поведения. А дальше мы можем ассоциировать алгоритм ИИ с родом, просто сохранив в нем указатель на нужную функцию.
Снова звучит знакомо? Теперь мы вернулись к реализации виртуальной таблицы в нашем объекте типа.
Еще более мощное решение — это реализовать поддержку поведения полностью в данных. Шаблоны Интерпретатор (Interpreter) GoF и Байткод (Bytecode) позволят нам создавать объекты, представляющие поведение. Если мы прочитаем данные из файла и используем их для создания структуры данных из одного из этих шаблонов, мы перейдем к определению поведения за пределами кода, полностью с помощью контента.
Со временем игры становятся все больше управляемыми за счет данных (data-driven). Железо становится все более мощным, и мы все больше сталкиваемся с ограничениями в плане количества контента, который мы можем подготовить, чем со стороны железа, которое мы нагружаем. Когда у нас был только картридж размером
64К, сложно было просто уместить в него весь геймплей. А теперь когда у нас есть по крайней мере двухслойныйDVD, сложность уже состоит в том чтобы наполнить этотDVDгеймплеем.Скриптовые языки и другие высокоуровневые способы определения поведения в игре могут значительно повысить нашу производительность, но за счет разумной платы в виде снижения производительности во время работы игры. Так как улучшается только железо, а не наши мозги, такая плата становится все менее и менее чувствительной.
Пример кода
Для нашей первой реализации мы начнем с простого и построим базовую систему, описанную в разделе мотивации. Начнем с класса Breed:
class Breed
{
public:
Breed(int health, const char* attack)
: health_(health), attack_(attack)
{}
int getHealth() { return health_; }
const char* getAttack() { return attack_; }
private:
int health_; // Начальное здоровье.
const char* attack_;
};
Очень просто. По сути — это контейнер для двух полей данных: начальное здоровье и строка атаки. Посмотрим, как его будут использовать монстры:
class Monster
{
public:
Monster(Breed& breed)
: health_(breed.getHealth())
, breed_(breed)
{}
const char* getAttack() {
return breed_.getAttack();
}
private:
int health_; // Текущее здоровье.
Breed& breed_;
};
Когда мы конструируем монстра, мы передаем ему ссылку на объект рода. Таким образом мы указываем род монстра вместо того чтобы делать его подклассом, как раньше. Внутри конструктора Monster использует род для определения начального здоровья. Чтобы получить строку атаки, монстр просто обращается к своему роду.
В этом простом кусочке кода и заключена вся суть шаблона. Все остальное всего лишь бонус.
Уподобление объекта тип настоящим типам: конструкторы
С помощью того, что у нас сейчас есть, мы конструируем монстра напрямую, и сами отвечаем за то, чтобы передать ему род. Такой метод значительно хуже, чем обычное создание экземпляров объектов в ООП языках: обычно мы не выделяем сначала область памяти, а затем даем ей класс. Вместо этого мы вызываем функцию конструктор самого класса и она отвечает за то, чтобы создать для нас новый экземпляр.
Этот же шаблон можно применить и к объекту типу:
class Breed
{
public:
Monster* newMonster() { return new Monster(*this); }
// Предыдущий код Bread...
};
"Шаблон" здесь вполне правильно слово. Потому что мы говорим не много ни мало, а о шаблоне программирования: Фабричный метод (Factory Method) GoF.
В некоторых языках этот шаблон применяется для создания всех объектов. В Ruby, Smalltalk, Objective-C и некоторых других языках, где классы являются объектами, вы создаете новые экземпляры, вызывая метод самого объекта класса.
А теперь класс, который его использует:
class Monster
{
friend class Breed;
public:
const char* getAttack() {
return breed_.getAttack();
}
private:
Monster(Breed& breed)
: health_(breed.getHealth())
, breed_(breed)
{}
int health_; // Текущее здоровье.
Breed& breed_;
};
Основное отличие — это новая функция newMonster() в Breed. Это наш фабричный метод "конструктор". В нашей первой реализации создание монстра выглядело следующим образом:
Вот и еще одно небольшое различие. Так как пример кода написан на
C++, мы можем использовать очень полезную возможность: дружественные классы.Мы сделали конструктор
Monsterприватным, чтобы быть уверенными в том, что его никто не вызовет напрямую. Дружественные классы обходят это ограничение и Breed все равно получает к нему доступ. Это значит, что единственный способ создать монстра — это использоватьnewMonster().
Monster* monster = new Monster(someBreed);
А после изменений оно будет выглядеть так:
Monster* monster = someBreed.newMonster();
Для чего это нужно? Создание объекта состоит из двух шагов: выделения памяти и инициализации. Конструктор Monster позволяет нам выполнять всю необходимую инициализацию. В нашем примере это просто сохранение рода, но в настоящем игровом мире мы загружали бы графику, инициализировали ИИ монстров и делали другую работу по настройке.
Однако все это происходит после выделения памяти. У нас уже есть участок памяти для хранения нашего монстра еще до того, как вызывается конструктор. В игре мы обычно контролируем этот аспект создания объекта: мы обычно используем вещи типа нестандартных выделителей памяти или шаблон Пул объектов (Object Pool) для управления тем, где будут храниться объекты.
Определяя функцию "конструктор" в Breed у нас появляется место, где можно разместить такую логику. Вместо простого вызова new, функция newMonster может взять память из пула или нестандартной кучи перед тем как передать управление ``Monsterдля инициализации. Помещая эту логику внутрьBreed``` — единственную функцию, которая имеет возможность создавать монстров, мы можем быть уверены, что все монстры буду создаваться с помощью нужной нам схемы управления памятью.
Разделяемые между экземплярами данные
Все, чего мы на данный момент добились — это довольно полезная, но все-таки довольно базовая система типов объектов. В конце концов, у нас могут появиться сотни родов, каждый с дюжинами атрибутов. Если дизайнер захочет настроить все тридцать видов троллей, чтобы они стали немного сильнее, ему придется весьма долго заниматься утомительным вводом данных.
Что здесь может помочь, так это возможность разделять атрибуты между множеством родов, также как роды позволяют нам разделять атрибуты между множеством монстров. Также как мы применяли наше ООП решение в первый раз, мы можем решить эту задачу наследованием. Только на этот раз вместо использования механизма наследования, предоставляемого языком, мы реализуем его самостоятельно с помощью объекта типа.
Чтобы ничего не усложнять, мы будем поддерживать единичное наследование. Точно также как наш класс может иметь родительский базовый класс, мы можем позволить роду иметь родительский род:
class Breed
{
public:
Breed(Breed* parent, int health, const char* attack)
: parent_(parent)
, health_(health)
, attack_(attack)
{}
int getHealth();
const char* getAttack();
private:
Breed* parent_;
int health_; // Начальное здоровье.
const char* attack_;
};
Когда мы конструируем род, мы даем ему родителя, от которого он наследуется. Роду, который не имеет предков мы передаем NULL.
Чтобы все это имело смысл, дочерний род должен управлять тем, какие атрибуты наследуются от родителя, а какие переопределяются и указываются им самим. В системе из нашего примера мы указываем, что род переопределяет здоровье монстра ненулевым значением и переопределяет атаку ненулевой строкой. Другими словами атрибуты наследуются от родителя.
Существует два способа это сделать. Один заключается в том, чтобы обрабатывать делегирование динамически, каждый раз при запрашивании атрибута следующим образом:
int Breed::getHealth()
{
// Переопределение.
if (health_ != 0 || parent_ == NULL)
return health_;
// Наследвоание.
return parent_->getHealth();
}
const char* Breed::getAttack()
{
// Переопределение.
if (attack_ != NULL || parent_ == NULL)
return attack_;
// Наследование.
return parent_->getAttack();
}
У такого способа есть преимущество в том, что он будет работать даже в том случае, если во время работы изменить род и он больше не будет переопределять все или какое-то один атрибут. С другой стороны, нам потребуется немного больше памяти (чтобы хранить указатели на родителей) и мы немного теряем в скорости. Нам придется обходить всю цепочку наследования каждый раз, когда мы запрашиваем атрибут.
Если мы можем полагаться на то что атрибуты рода меняться не будут, можно выбрать более быстрый вариант и применять наследование во время создания (construction time). Такое делегирование называется "копированием вниз", потому что мы копируем унаследованные атрибуты вниз в производный тип в момент его создания. Это выглядит следующим образом:
Breed(Breed* parent, int health, const char* attack)
: health_(health)
, attack_(attack)
{
// Наследование непереопределенных атрибутов.
if (parent != NULL) {
if (health == 0)
health_ = parent->getHealth();
if (attack == NULL)
attack_ = parent->getAttack();
}
}
Обратите внимание, что теперь нам не нужно поле для родительского рода. Как только конструктор выполнился, мы можем забыть о родителе, потому что уже скопировали из него нужные нам атрибуты. Чтобы получить доступ к атрибутам рода мы просто возвращаем значение поля:
int getHealth() { return health_; }
const char* getAttack() { return attack_; }
Просто и быстро!
А теперь предположим, что наш движок выполняет настройку родов, загружая их из JSON файла, в котором они определены. Вот как он выглядит:
{
"Troll": {
"health": 25,
"attack": "The troll hits you!"
},
"Troll Archer": {
"parent": "Troll",
"health": 0,
"attack": "The troll archer fires an arrow!"
},
"Troll Wizard": {
"parent": "Troll",
"health": 0,
"attack": "The troll wizard casts a spell on you!"
}
}
У нас будет код, читающий каждую запись о роде и создающий новые экземпляры рода для каждой из них. Как вы можете видеть из значения поля "parent", равного "Troll", рода Troll Archer и Troll Wizard наследуются от базового рода Troll.
Так как у них обеих в поле здоровья стоит ноль, они наследуют его от базового рода Troll. Это значит, что теперь дизайнеры могут настраивать здоровье в Troll, а все остальные рода тоже будут обновляться. По мере того, как будет увеличиваться количество родов и количество атрибутов в каждом роде, такой подход позволит нам сэкономить много времени. И теперь, в лице небольшого фрагмента кода, у нас есть открытая система, дающая достаточную свободу нашим дизайнерам и сохраняющая им время. А мы тем временем возвращаемся к кодированию другого функционала.
Архитектурные решения
Шаблон Объект тип позволяет создавать систему типов, подобно тому, как если бы мы писали собственный язык программирования. Простор для архитектурных решений достаточно широк и мы можем делать очень много всяких интересных вещей.
На практике вашего внимания заслуживают всего несколько вещей. Время и удобство поддержки ограничивают нас от слишком сложных вещей. Самое главное при разработке объекта типа, чтобы наши пользователи (обычно это не программисты) могли легко понять как с ним работать. Чем проще он будет, тем он для нас полезнее. Поэтому мы будем рассматривать только хорошо проторенные дорожки, а все остальное оставим академикам и исследователям.
Наш Объект тип будет инкапсулирован или открыт?
В нашем примере реализации Monster ссылался на род, но публично он не виден. За пределами кода мы не можем напрямую получить род монстра. Для всей остальной кодовой базы, монстры вообще не имеют типа и то что они относятся к определенному роду — не более чем детали реализации.
Мы легко можем это изменить, позволив монстрам возвращать свой род (Bread):
Как и в других примерах в книге, мы следуем соглашению, когда объект возвращается по ссылке, а не в виде указателя, чтобы дать понять пользователю что NULL никогда возвращаться не будет.
class Monster
{
public:
Breed& getBreed() { return breed_; }
// Существующий код...
};
Таким образом, мы изменяем дизайн Monster. Тот факт, что монстры имеют род, теперь является публично видимой частью API. Оба решения имеют свои преимущества.
Если объект тип инкапсулирован:
Сложность шаблона Объект тип скрыта от остальной кодовой базы. Она становится деталями реализации, за которую отвечает только сам объект тип.
Типизированный объект может частично переопределять поведение из объекта типа. Предположим, что мы захотели изменить строку атаки для монстра, когда он находится на грани смерти. Так как строку атаки мы всегда получаем через Monster, вполне логично, что мы разместим код именно там:
const char* Monster::getAttack() { if (health_ < LOW_HEALTH) { return "The monster flails weakly."; } return breed_.getAttack(); }Если бы внешний код вызывал
getAttack()напрямую из рода, у нас не было бы возможности реализовать такую логику.Нам нужно писать метод перенаправления для всего в чем участвует объект тип. Это самая утомительная черта такой архитектуры. Если в нашем объекте типе много функций, класс объект должен будет заводить собственные методы для всех из них, кого мы захотим сделать публично видимыми.
Если объект тип является видимым:
Внешний код может взаимодействовать с объектом типом без помощи экземпляра типизированного класса. Если объект тип инкапсулирован, мы никак не можем использовать его без типизированного объекта, являющегося для него оболочкой. Например, это не дает использовать наш шаблон конструктор, когда новый монстр создается с помощью вызова метода рода. Если пользователи не могут обратиться к роду напрямую, они не смогут его вызвать.
Объект тип теперь является частью публичного
APIобъекта. В целом, узкий интерфейс легче поддерживать, чем широкий: чем меньше вы показываете остальной части кодовой базы, тем меньше сложность и проще поддержка. Делая объект тип видимым, мы расширяемAPIобъекта и включаем в него все возможности объекта типа.
Как создается типизированный объект?
Когда мы применяем этот шаблон, каждый "объект" у нас представляется двумя объектами: главным объектом и объектом типом, который он использует. Каким же образом мы можем их создать и связать вместе?
Конструируем объект и передаем в него объект тип:
- Выделение памяти контролирует внешний код. Так как вызывающий код самостоятельно конструирует оба объекта, он может управлять и тем, где в памяти они будут находиться. Если мы хотим, чтобы наши объекты можно было использовать в разных сценариях работы с памятью (различные типы выделения памяти, на стеке и т.д.), в этом случае мы получаем нужную нам гибкость.
Вызов "конструирующей" функции объекта типа:
- Объект тип управляет выделением памяти. Это обратная сторона медали. Если мы не хотим, чтобы пользователь выбирал, где в памяти создавать наши объекты, а хотим управлять этим процессом сами, мы заставляем его пользоваться нашим фабричным методом объекта типа. Это может быть полезным, если мы хотим чтобы все объекты находились в одном Пуле объектов (Object Pool) или хотим еще использовать какие-либо другие способы выделения памяти.
Можно ли менять тип?
До сих пор мы предполагали, что как только объект создается и связывается с объектом типом, эта связь уже никогда не меняется. Объект как создается с одним типом, так с ним и умирает. Но это совсем не обязательно. Мы вполне можем позволить объектам менять свой тип.
Снова вернемся к нашему примеру. Когда монстр погибает, дизайнер может попросить нас о том, чтобы труп превратился в ожившего зомби. Мы можем реализовать это, создавая нового монстра рода зомби, когда монстр погибает. Но есть и другой вариант. Мы можем просто взять нашего монстра и изменить его род на род зомби.
Если тип не меняется:
Такой вариант проще как для программирования, так и для понимания. На концептуальном уровне, "тип" — это нечто что большинство людей воспринимают как нечто неизменное. И мы закрепляем такое предположение в коде.
Его проще отлаживать. Если мы попробуем отследить баг, при котором монстр оказывается в каком-то странном состоянии, нам будет гораздо проще разобраться в проблеме, если монстр сейчас относится к тому типу, к которому относился всегда.
Если тип можно менять:
Мы будем реже создавать объекты. В нашем примере, если тип не меняется, нам нужно будет потратить циклы процессора на создание нового зомби, копирование в него атрибутов из оригинального монстра, которого он будет представлять и затем удалять его. Если мы теперь сможем просто изменить тип, вся работа сведется к простому переназначению.
Нам нужно быть осторожнее с предположениями. У нас имеется довольно сильная связь между объектом и его типом. Например, род может предполагать что текущее здоровье монстра никогда не может превышать начальное здоровье, соответствующее его роду.
Если мы позволим менять род, нам нужно будет проверять, чтобы новый тип удовлетворял требованиям, предъявляемым к существующему объекту. Когда мы изменяем тип, нам скорее всего придется добавить какой-то код валидации, который будет проверять чтобы объект находился в том состоянии, в котором имеет смысл менять его тип.
Какой тип наследования у нас поддерживается?
Никакого наследования:
Это просто. Зачастую простота — самый лучший выбор. Если у вас нет кучи данных, которые необходимо разделять между объектами типа, зачем самостоятельно усложнять себе жизнь?
Может привести к дублированию работы. Стоит еще поискать такую систему генерации контента, в которой дизайнеры хотели бы отказаться от наследования. Когда у вас есть пятьдесят различных типов эльфов, настраивать их здоровье, немного изменяя одно и то же значение в пятидесяти разных местах — это отстой.
Простое наследование:
Все еще достаточно просто. Его легко реализовать и, что более важно, легко понять. Если с системой будут работать нетехнические специалисты, чем меньше в ней будет движущихся частей, тем лучше. Не зря большое количество языков программирования поддерживают только единичное наследование. Это вполне удачный компромисс между мощью и простотой.
Поиск атрибутов работает медленнее. Чтобы получить из объекта типа нужные данные, нам нужно обойти всю цепочку наследования, чтобы найти тот тип, из которого значение нужно брать. Если такое происходит в коде, для которого критична производительность, мы не можем позволить себе тратить на это время.
Множественное наследование:
Мы можем избежать практически любого дублирования данных. С помощью хорошей системы множественного наследования, пользователи могут построить систему наследования, в которой практически не будет избыточности. И когда придет время настройки чисел, большей части копипаста можно будет избежать.
Это сложно. К сожалению, выигрыш является более теоретическим, чем практическим. Множественное наследование сложнее понимать и осмысленно использовать.
В нашем примере тип Зомби Дракон, наследуется и от Зомби и от Дракона, какие атрибуты будут браться из Зомби и какие из Дракона? Для того, чтобы применять эту систему, пользователям нужно понимать работу графа наследования и способность предвидеть какая иерархия будет удачной.
Большая часть стандартов кодирования на
C++, которые я сейчас вижу, запрещает использовать множественное наследование, а вC#иJavaоно отсутствует полностью. Так что стоит это признать: оно настолько сложное, что лучше не использовать его вообще. Если вы хорошо об этом подумаете, то поймете что у нас редко возникает реальная необходимость использовать множественное наследование для объектов типов в игре. Так что чем проще, тем лучше.
Смотрите также
На самом высоком уровне этот шаблон отвечает за разделение данных и поведения между несколькими объектами. Еще один шаблон — Прототип ( Prototype) GoF, посвящен решению той же проблемы, но несколько по другому.
Объект тип — близкий родственник Приспособленца (Flyweight) GoF. Оба позволяют вам разделять общие данные между экземплярами. В случае с Приспособленцем, наследование экономит память, а разделяемые данные не обязательно должны концептуально представлять из себя "тип" объекта. В случае с Объектом типом, усилия концентрируются на организации и гибкости.
Есть много общего у этого шаблона и с шаблоном Состояние (State) GoF. Оба шаблона позволяют объекту делегировать часть себя к другому объекту. В случае с объектом типом, мы обычно делегируем, что объект из себя представляет: инвариантным данным, описывающим объект в широком смысле. В случае Состояния, мы делегируем то, чем является объект в данный момент: временные данные, описывающие текущую конфигурацию объекта.
Когда мы обсуждали возможность объекта менять собственный тип, вы можете думать об этом как о частичном дублировании Объектом типом функциональности шаблона Состояния.